This year marks ten years since Elixir was created and we wanted to celebrate at ElixirConf EU. We sponsored the conference in London to connect with the community, share how we're building a Flights API, and learn more about Elixir. We enjoyed loads of great talks and these are the highlights.
Celebrating the 10 years of Elixir – José Valim
José Valim created the Elixir programming language back in 2012. He kicked off this year’s conference with an interesting question to get us thinking: ‘What’s your future with Elixir?’.
José shared insights into three future projects for Elixir:
- set-theoretic types
- developer learning and experience
- machine learning
He couldn’t expand the later topics without addressing the elephant in the room: types and static type checking. Can static type checking be good for Elixir? It’s complicated, but yes – it can be good. It’s great to see that if one day it arrives in Elixir, it won’t restrict the language we know and love. The set-theoretic types work is still in the research phase and you can read more details on Jose’s tweet announcement.
After the elephant leaves the room, José shared his plans to improve the developer experience and make Elixir more accessible to new people by improving LiveBook. The features making it easier to write Elixir code in Livebook like code autocompletion and documentation lookup on hover can be reused on IDEs like Visual Studio Code through Elixir language server. This kills two birds with one stone.
Lastly, José moved on to machine learning. He’ll keep pushing Elixir to be a good choice for machine learning projects. This work started a couple of years ago when the Nx library was released – with a cute Numbat mascot – that lets you run Elixir code GPU to calculate multidimensional matrixes in a very efficient way. Thanks to Nx, we have projects like Axon, neural network library, and Explorer for fast data exploration.
Seeing what José is working on and the projects in his future with Elixir got us thinking: what’s our future with Elixir? I – Ulisses – would like to write a library to parse XML in a more performant way and maybe talk about it at the next conference. What about you? What’s your future with Elixir?
It's a-Live(book) – Adam Lancaster
Elixir Livebook is becoming an excellent tool to lower the barrier for anyone to get started with Elixir. Adam from our team shares his insights in the context of Duffel: writing live documentation when working with airline APIs.
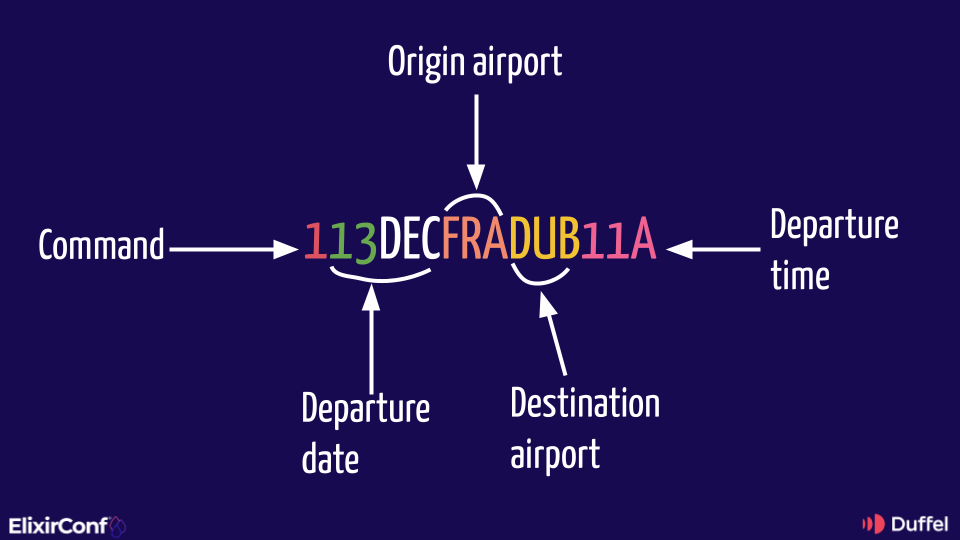
He gave a wonderful introduction to the evolution of airline systems. From the first operationally heavy flight booking system to the personal computer, and finally the web APIs we have today. Airlines are doing very complex stuff and it isn’t easy to make an API for that. A highlight was when Adam explained the following command from a Global Distribution System (GDS) – the dominant distribution channel for flight content:
113DECFRADUB11A
Can you guess what that does? Check out the slide that Adam shared: you might be surprised to learn the command is a flight search.
The talk continued with Adam explaining Livebook features like:
- Markdown styles
- Mermaid diagrams
- And of course, Elixir code
- How to connect to running Elixir nodes
- How to install Elixir’s dependencies
Then, Adam shared details on an advanced topic: how to write private code and make it available on your Livebook instances. In his example, Adam wrote functions that make it possible for code to read secrets from Google’s Secret Manager using the developer’s machine access rights. This helps make sure the right person has the right access while using a very convenient tool.
Finally, Adam showed how these features tie together with Duffel’s Flight API. Given the complexity of airline APIs and a lack of comprehensive documentation, Livebook plays an important role to allow developers to explore and record their discoveries before committing to a high-confidence implementation. One amazing feature: developers can experiment with previous experiments with a single click.
Sonic Pi: past, present & future – Sam Aaron
The first day of the conference ended with Sam Aaron’s keynote about the history and future of Sonic Pi. If you’ve never heard about it, Sonic Pi is a tool that allows you to code music. Yeah, you read that right, code music! You can even perform it live with the right skills and talent. It’s basically a new kind of instrument. Check out the video recording when it’s available so you can see how impressive the performance can be.
Sonic Pi started as an educational tool for kids. The mission was clear but hard: make coding exciting for kids the same way kids are excited to see a famous football player or singer. The project has done well and keeps evolving. Sonic Pi is now used by a broad range of users including hobbyists, teachers, musicians, and live performers. Despite the success, Aaron still struggles with getting enough funding to keep the project evolving.
But wait, what do Sonic Pi and Elixir have in common? Aaron shared how the future of Sonic Pi is to connect multiple people, locally or over the internet, and let them jam together. It will be a distributed live concert. Can you imagine it? When we talk about distributed systems, Erlang and Elixir shine. Aaron shared his memories with Joe Armstrong, Erlang’s creator, who's helping build the new distributed feature. It was a sentimental moment.
It’s so inspiring to see someone so passionate about an idea and to see that Elixir and Erlang will help with the future of Sonic Pi. It’s an amazing project and it’s exciting to see what Aaron will build.
Code & homicide: what software developers can learn from offender profiling – Adam Tornhill and Crux Conception
To start the second day’s talks, Adam Tornhill and Crux Conception took to the stage to examine the parallels between software engineering and criminal psychology. It was really intriguing – there isn't an obvious connection.
Adam is a developer and author and Crux is a criminal profiler. Apparently Criminal Minds isn’t too far away from what they actually do. It was really interesting to hear about the ways in which we might ‘profile’ a codebase as software engineers, especially in the context of managing technical debt where the ‘crime scene’ is hidden in plain sight.
Adam had some really neat visualisations to show high-interest areas of code (’hotspots’) and code health indicators which track antipatterns like deeply-nested complexity and brain methods. The example CodeScene data for Phoenix, React, and CoreCLR was really impressive and clearly showed problematic areas of the codebase. It also showed which of those might generate the highest return on developer investment and, reassuringly for Duffel, even under this intensely scrutinising light the Phoenix codebase came off very nicely.
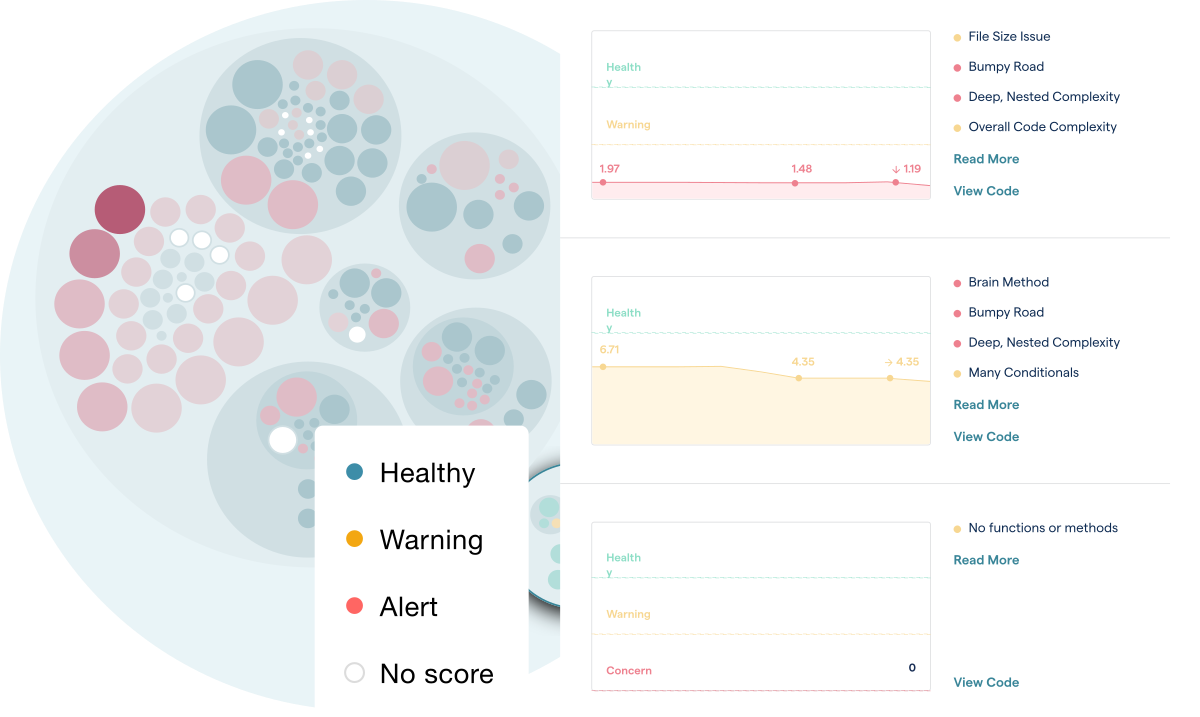
This talk presented a compelling alternative to a traditional static codebase analysis which can often struggle to present actionable feedback in a legacy codebase due to the sheer number of warnings generated. It was also surprising to see just how quickly code can become ‘legacy’ if the authors leave and there are no longer active contributors. For example, Phoenix has 41 kLoC of code and over 600 active contributors, but when Adam simulated removing Chris McCord (Phoenix creator) and José Valim (Elixir creator) from the contributor pool, the legacy indicators for vast sections of the codebase turned from green to red.
Plus, on top of all this, we heard some fascinating insights from Crux on using a combination of human psychology, geographical profiling, and political motivations to track dangerous offenders.
Exploring Elixir project re-compilation – Anton Satin
Next was Anton Satin’s talk about Elixir recompilation. This is a very important topic as when codebases grow you want to maintain a fast developer feedback loop; waiting ages for your code to compile as you’re cycling through code-build-test-repeat isn’t fun. Handling codebase growth is particularly relevant for Duffel as we continue to add airline integrations and API features.
Anton set the stage by sharing some important distinctions between Elixir module dependency types:
- compile – when a module needs another during code compilation, e.g. via a macro or behaviour definition
- export – when a module needs another’s struct keys, e.g. in pattern matching, or imports a function
- runtime – when a module needs another’s function only at runtime
It’s also possible for these dependencies to form dependency structures:
- cycles – when a module ends up depending on itself through a chain of other module dependencies
- double dependencies – when a module depends on the same module twice in two different ways perhaps through two different dependency chains
As many of you will know, the culprit causing long compilation times isn’t usually the compiler, it’s the number of files it has to compile. Anton emphasised how easily dependencies can ripple out across many files if you’re not careful. Introducing a seemingly innocuous compile-time dependency can link up a chain of dependencies hundreds of files long, leading to a recompilation time of minutes not seconds and a frustrated developer. Fixing these ripple effects is key to reducing the time spent recompiling code.
Anton had a few suggestions from his own work which might help other developers improve recompilation time by modifying the dependency graph of their codebases:
- Separate runtime code and compile-time code into different files, for example, by moving the behaviours to a different module. This helps modules that depend on behaviour to not get recompiled when the module’s runtime function changes.
- Use export dependencies as they’re generally much less problematic. If module
Aimports a function from moduleB, then changingBwon’t causeAto be recompiled unless the public interface toBchanges. - Explore tooling to help look into dependencies:
mix xref(docs) can show you the dependency graph of your entire codebase or an individual file, and even highlight the types of dependencies and any cycles. - Examine compile-time dependencies with
mix xrefas they’re the main culprit in causing ripple effects.
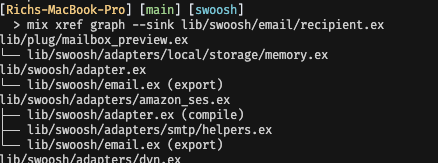
mix xref on a Swoosh module.As a general rule of thumb, you should avoid dependency cycles and focus on more runtime module dependencies to avoid unnecessary ripple effects during recompilation. It’s also easier to prevent these effects than fix them, so it’s worth giving thought to your app’s compilation dependency graph early on.
The mix xref command is your best friend to help solve unwanted recompilation issues, and can even influence your application design by showing how the compiler views things — very useful to know and definitely something we’re going to look into at Duffel.
Distributing work with queues and GCP Pub/Sub – Johanna Larsson
Later in the day, our very own Johanna Larsson gave a talk on how Duffel distributes tasks between workers using a persisted work queue with Google Cloud Pub/Sub. This was a great chance to dive into an area of the Duffel platform that not everyone on the team works with day-to-day.
Johanna started by giving some context on the problem space: Duffel needs to turn a customer’s flight search request into multiple separate airline searches and aggregate the results before returning them to the customer. Given that a single airline search can take up to 20 seconds to return tens of megabytes of XML, this is already an interesting problem. Add into the mix the fact that airlines don’t fly every route and customers don’t use all airlines – meaning a search request can return zero or many airline searches – the problem becomes even more difficult.
Now, you might be wondering: why not just use your favourite load balancing algorithm to allocate each customer’s search to a server, and spin up a set of tasks there to execute each airline search? Problem solved!
As Johanna explains, this doesn’t quite have the performance characteristics we need. In fact, it can lead to very imbalanced load across servers. The workload per customer search is highly dependent on how many airlines the search actually ends up querying, so you can easily end up in a situation where one server is processing thousands of response offers and another server is doing little or no work.
So what’s the solution? As you might have guessed from the talk title, it involves introducing a GCP PubSub-based queuing system where:
- Airline search requests are now placed onto a distributed work queue instead of being executed in the API servers
- Each airline search is pulled from the queue to be executed by a search worker with spare resources.
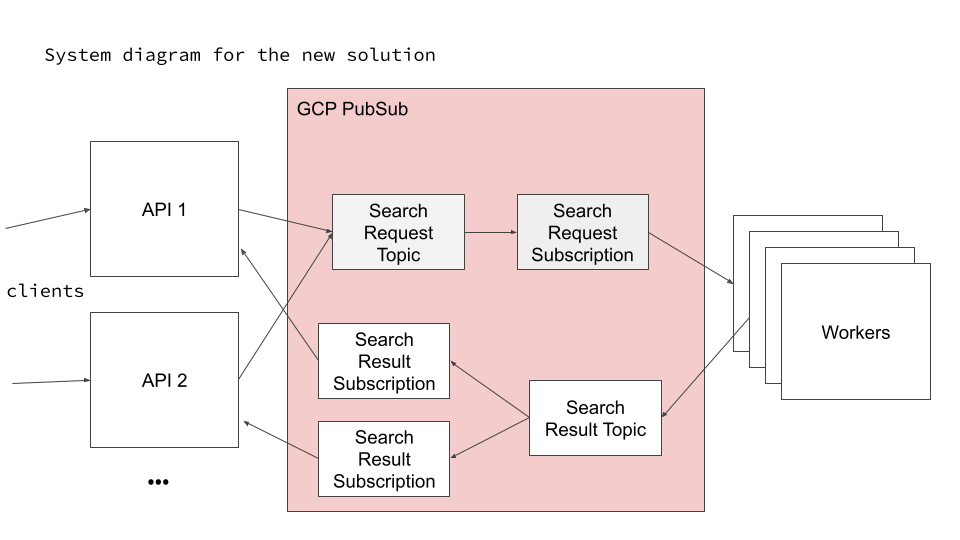
The crux is that the atomic unit of work is modified from being a customer’s search request to an airline search. This helps tremendously with load balancing: those pesky heavy-load searches with multiple airlines and tonnes of XML to process are now split across many servers, each doing a bit of the work.
Another benefit of using a queue-based system is that it inverts the need for the orchestration servers to implement backpressure themselves. Each worker uses Broadway to pull work from the queue based on configurable concurrency parameters, ensuring it will only ever bite off as many airline searches as it can chew.
Additionally, we get some nice secondary benefits from isolating CPU-intensive work to a specific worker server pool. This work is no longer contributing to load on the API servers and we have much clearer observability of the performance of these workers.
But wait – what about latency? Won’t passing all these messages between servers make searches take way longer?
No, says Johanna. After tuning Broadway’s concurrency parameters to give the optimal maximum number of concurrent tasks on each worker, these load-balancing improvements come with no overall increase in latency at p99.
This is very cool stuff and we got to see three photos of Johanna’s two cats, Blue and Monkey – recently renamed from Blue and White, presumably for cheeky behavioural reasons.

Elixir at Duffel
We love Elixir and we use it every day at Duffel. Our team is hybrid with an office in London where we’re busy disrupting the travel industry. Check out our career opportunities for new roles or submit an open application.


Latest posts
Traveltek Announces Duffel Integration Into iSell Platform
We are thrilled to announce that, Traveltek, a global leader in travel technology, just launched the latest upgrade to its award winning iSell Platform with the integration of Duffel.

Behind the Scenes: How Hotel Booking Works
Ever wondered what happens when you click the "Book Now" button for your next hotel stay? Dive into our latest blog post where we uncover the technology, strategy, and major players behind the scenes of hotel booking.

The Dynamic Duo: Why Travel and Spend Management are Inseparable
Check out this insightful article on the inseparable relationship between travel and spend management.

Traveltek Announces Duffel Integration Into iSell Platform
We are thrilled to announce that, Traveltek, a global leader in travel technology, just launched the latest upgrade to its award winning iSell Platform with the integration of Duffel.
Travel Industry
Behind the Scenes: How Hotel Booking Works
Ever wondered what happens when you click the "Book Now" button for your next hotel stay? Dive into our latest blog post where we uncover the technology, strategy, and major players behind the scenes of hotel booking.
The Dynamic Duo: Why Travel and Spend Management are Inseparable
Check out this insightful article on the inseparable relationship between travel and spend management.