On the 22nd November 2021, the Duffel API was unavailable for a period of 2 hours and 17 minutes, from 22:02:27 GMT until 00:20:51 GMT on the following day.
As an API provider, the reliability of our services directly impacts our merchant's reliability. If we are down, they are also likely to be down, their users cannot search for and book flights, and our merchants lose out on revenue.
Our engineering culture is one that embraces failure, we seek to learn from it, to continuously improve and become more resilient to such events. In this blog post we will share our findings. We will do so as transparently as possible, with the aim of documenting our learnings and helping others learn from our mistakes.
This blog post requires deep technical knowledge about SQL databases, specifically PostgreSQL, as well as context on how the Duffel API works internally. We recommend that you take the time to follow the links to resources, using them as reference when reading this post.
Assuming you have Docker available to you, if you'd like to follow along, you can spin up the same database we're using for examples with the commands below:
# Start the database:
docker run -p 5432:5432 --name mydb --rm aa8y/postgres-dataset:world
# Then you can connect to it by running:
docker exec -it mydb psql world
# The command above should bring up a psql prompt,
# where you can run queries like:
psql (11.1)
Type "help" for help.
world=# SELECT 1;
?column?
----------
1
(1 row)What is Duffel?
Duffel is an API that enables developers to build services that search and book flights. If you are interested in knowing more, we recommend you check our API documentation.
Our Data Model
To understand what caused the outage, we first need to understand how searching for flights works behind the scenes.
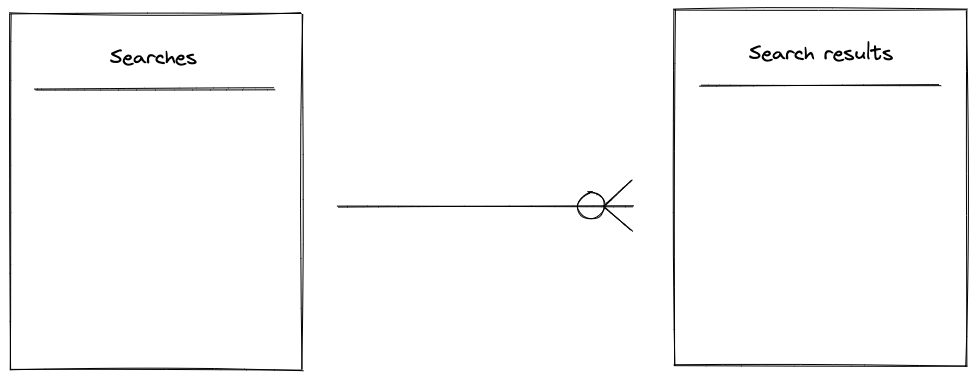
In order to search for flights you need to create an offer request. An Offer Request is a resource that represents a "search", it contains information on how many passengers are flying, where and when they want to travel.
When an Offer Request is created, in turn Duffel sends a search request to a range of airlines, and returns search results, that we call Offers. For simplicity we’ll refer to these two resources as "search" and “search results” respectively.
Storage of search results
Internally, all search results are persisted in a PostgreSQL database to be used later for booking flights[1].
Search results are only valid for 30 minutes. At high volume periods, this leads to the accumulation of a lot of expired search results. In order to save space and reduce our costs, we must regularly delete this data.
To do this efficiently we take advantage of PostgreSQL’s Table Partitioning. This allows us to drop partitions – an operation that is significantly faster than if we ran a DELETE statement on a single larger table[2].
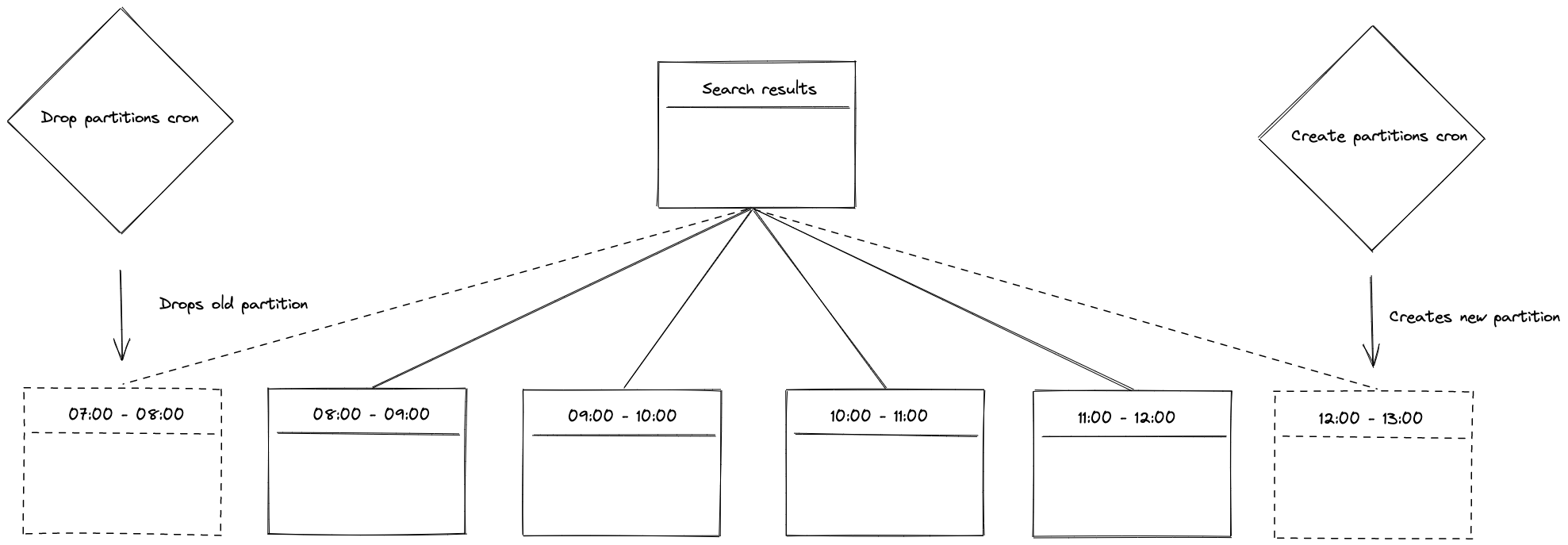
Each partition holds search results for a period of 1 hour, and we have two time-based jobs, one responsible for creating new partitions and another responsible for deleting old ones.
PostgreSQL Locks
To understand what we saw, we also need to introduce the concept of locks. Locks are used by PostgreSQL to control concurrent access to data. Specifically, to prevent two conflicting operations from happening at the same time. For example, the jobs that create and delete partitions execute data definition language (or DDL) statements and they take an ACCESS EXCLUSIVE lock on the table. Which means that no reads/writes can happen on a table while the operation is running. These operations are usually very fast, which often means you don't notice them.
What did we see?
On the 22nd November 2021 around 22:02 GMT read and write transactions to the search results table were failing. Our logs showed that they were waiting to acquire a lock:
2021-11-22 22:02:28.299 UTC [1447996]: [3-1] LOG: process 1447996 still waiting for RowExclusiveLock on relation 98765 of database 12345 after 1000.137 ms
2021-11-22 22:02:28.299 UTC [1447996]: [4-1] DETAIL: Process holding the lock: 1449162. Wait queue: 1467042, 1447996, 1461683, 1447814, 1464184, 1467066, 1454459, 1466252, 1466217, 1448834, 1455991, 1452495, 1464892, 1449372, 1447317, 1453001, 1458507.
2021-11-22 22:02:28.299 UTC [1447996]: [5-1] STATEMENT: INSERT INTO "search_results" ("cabin_class","id","live_mode","organisation_id","passengers","inserted_at","updated_at") VALUES ($1,$2,$3,$4,$5,$6,$7)Specifically, waiting to acquire a ROW EXCLUSIVE LOCK (required for writing) on relation 98765 (the object ID, OID, of our search results table).
This meant that our API was down as no searches could be inserted into our database.
After more digging we found out that the job responsible for creating partitions was also waiting to acquire a lock:
2021-11-22 22:02:28.248 UTC [1467042]: [3-1] LOG: process 1467042 still waiting for ShareRowExclusiveLock on relation 98765 of database 12345 after 1000.067 ms
2021-11-22 22:02:28.248 UTC [1467042]: [4-1] DETAIL: Processes holding the lock: 1449162, 1446282. Wait queue: 1467042, 1447996, 1461683, 1447814, 1464184, 1467066, 1454459, 1466252, 1466217, 1448834, 1455991, 1452495, 1464892, 1449372, 1447317, 1453001.
2021-11-22 22:02:28.248 UTC [1467042]: [5-1] STATEMENT: CREATE TABLE IF NOT EXISTS search_results_partition_20211123_0202_to_20211123_0302 PARTITION OF search_results FOR VALUES FROM ('2021-11-23 02:02:00') TO ('2021-11-23 03:02:00')If we take a closer look at these logs, process id 1467042 - the one trying to create a new partition in the search results table - is the process that is in the queue that is blocking all the reads and writes to the searches table[3]. We were getting somewhere here.
Based on the logs emitted, we built a dependency graph between the blocked processes, and we found that another process 1449162 – the “mysterious statement” in the graph below – was holding a lock that prevented the create table partition statement from executing, and in turn was blocking all operations to the search results table.
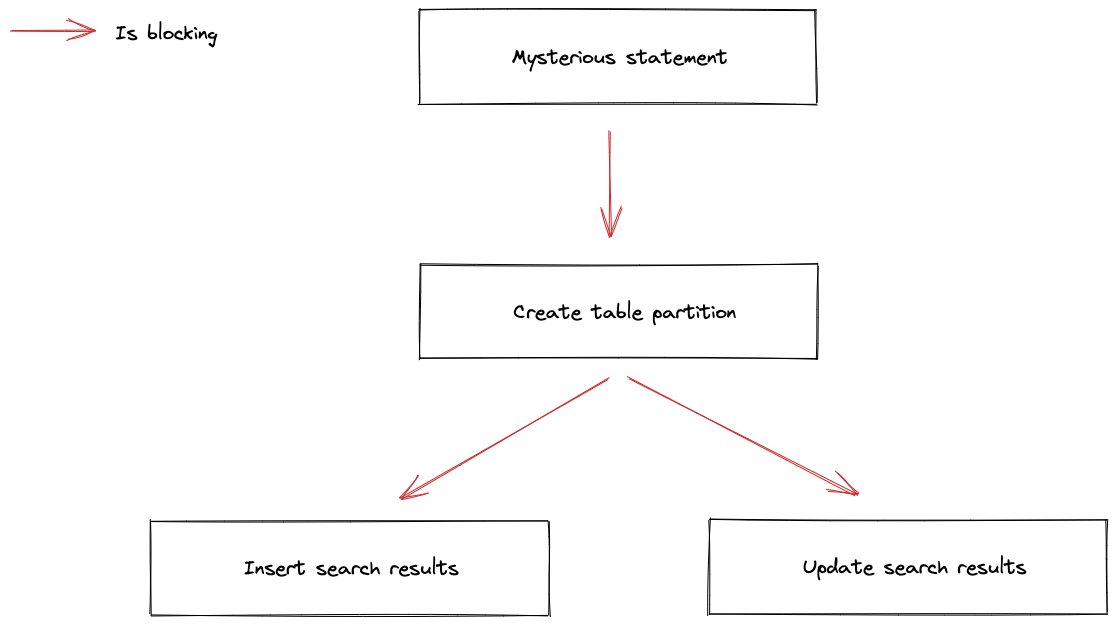
Finding the "mysterious" statement
The only thing we knew so far was the id of the process running it, but we didn't know exactly what statement was causing the holdup. Searching through our PostgreSQL logs revealed the following:
2021-11-22 23:39:38.801 UTC [1449162]: [2-1] FATAL: terminating autovacuum process due to administrator commandInteresting. While troubleshooting the incident, we had performed a restart of the database which resulted in the log line above, which tells us a few things: (1) autovacuum was running with process id 1449162, (2) that it was terminated and (3) that the termination was caused by the restart.
If you look at the log's process id: 1449162, this is the process that is blocking the partitions creation.
This came as a huge surprise to us, as we knew that the autovacuum process did not block reads/writes, but we had a compelling case that autovacuum was at least part of the problem.
Understanding VACUUM
Before we deep dive into VACUUM, we need to understand a few key concepts first.
- "Everything" is a transaction in Postgres
- A common misconception is that transactions only start after BEGIN statements. In reality a single statement counts as a transaction, even if not wrapped in BEGIN/COMMIT.
- Every transaction in the database is applied in serial order, with a global lock ensuring that only one is being confirmed committed or aborted at a time
- Transaction IDs (TXID) are represented by an incrementing 32-bit unsigned integer, that is global to PostgreSQL's state, see examples below where every new transaction is assigned a new id (you can try running this yourself):
world=# SELECT txid_current(); 599 world=# SELECT txid_current(); 600 world=# SELECT txid_current(); 601 - Multi-version concurrency control (MVCC): A mechanism that allows for scalable concurrent access by giving each transaction its own snapshot of the database state, ensuring that reads don't block writes and vice-versa.This mechanism relies on Transaction IDs - and other things - in order to determine what is visible and what isn't between transactions running concurrently.
- One way to think about this is that when a row (or tuple) is created, it keeps a record - a marker - of the transaction that introduced it (
xmin). - When a row is deleted, it also keeps track of the transaction that removed it (
xmax). - This information is available to us, see below:
SELECT id, name, population, xmin, xmax FROM city WHERE id = 253; id | name | population | xmin | xmax -----+----------------+------------+------+------ 253 | Campina Grande | 352497 | 571 | 0- Notice the xmin, xmax above. This means that the row was added by TXID 571, and the special value of 0 indicates it has not yet been deleted (it is still "alive"). In most cases, if
xmaxwere set to any other value, this row would only be visible to transaction IDs between xmin and xmax. Though there are some nuances regardingxmax.
- One way to think about this is that when a row (or tuple) is created, it keeps a record - a marker - of the transaction that introduced it (
Given TXIDs are taken from a global incrementing 32-bit unsigned integer, what would happen when it reaches its maximum value (4,294,967,296)? In short: data loss.
Since TXIDs determine the viability of rows within our database, once this value wraps around back to 0, data that was inserted, say by TXID 571, is no longer visible (it appears to be in the "future"!).
This issue is known as transaction ID (TXID) wraparound, and it has been written about extensively, including by Sentry and CrunchData.
Back to 'VACUUM' – why did autovacuum block the creation of partitions? VACUUM is an essential part of Postgres’ MVCC implementation that exists to, among other things, ensure that:
- Old dead rows are marked as free space so that it can be reused
- Rows that have an xmax (ones that have been deleted) are taking up space unnecessarily, as not only is it "in the past", but transactions should no longer be able to see it.
- Old live rows are marked as frozen, so that PostgreSQL understands that older live rows are in the past rather than in the future, regardless of their xmin.
- i.e. if the row id 253 above survives long enough to see the TXID value tick back to 0, it is still visible - despite 0 being smaller than 571.
Vacuuming can be run manually or automatically (by the autovacuum daemon). There are a number of settings that you can use to determine how/when autovacuum runs.
One setting is worth calling out specifically: autovacuum_freeze_max_age, its default is set to 200 million. This determines that, if the last time the table was scanned completely for unfrozen rows was more than this many transactions ago, autovacuum will start an anti-wraparound vacuum on the table.
Let's take a look at the Postgres docs on routine vacuuming:
Autovacuum workers generally don't block other commands. If a process attempts to acquire a lock that conflicts with the SHARE UPDATE EXCLUSIVE lock held by autovacuum, lock acquisition will interrupt the autovacuum.
As expected, the autovacuum is non-blocking. Though the documentation continues…
However, if the autovacuum is running to prevent transaction ID wraparound (i.e., the autovacuum query name in the pg_stat_activity view ends with (to prevent wraparound)), the autovacuum is not automatically interrupted.
Bingo! We already know that it was running, and that it may not release its lock, but can we prove that it was running for the purpose of preventing TXID wraparound?
Proving our findings
To prove that the autovacuum daemon was running in an uninterruptible mode, we needed to understand the rate at which the table "ages", from this we could estimate when it'd cross the autovacuum_freeze_max_age threshold.
We did this by collecting a time series of the age(relfrozenxid) for the 'searches' table.
SELECT c.oid, relname, relfrozenxid, age(c.relfrozenxid) FROM pg_JOIN pg_namespace n on c.relnamespace = n.oid WHERE relname = 'city';
oid | relname | relfrozenxid | age
-------+---------+--------------+-----
16386 | city | 571 | 8
SELECT * FROM txid_current();
txid_current
--------------
579
-- Note that with each transaction the table gets "older"
SELECT c.oid, relname, relfrozenxid, age(c.relfrozenxid) FROM pg_class c JOIN pg_namespace n on c.relnamespace = n.oid WHERE relname = 'city';
oid | relname | relfrozenxid | age
-------+---------+--------------+-----
16386 | city | 571 | 9With this information, we are able to estimate when we'd have hit the threshold established by autovacuum_freeze_max_age. We then restored our database to the closest backup that we had prior to the incident, when we ran age(relfrozenxid) this value was extremely close to 200,000,000.
At our rate of "ageing", we were able to extrapolate that the autovacuum process would be running for the purpose of preventing XID wraparound at roughly 22 Nov 2021, 21:48:12, minutes before the incident.
With this fact at hand, combined with the knowledge that we were running DDL statements to create partitions, we can now prove exactly how the incident occurred.
As it turns out, autovacuum isn't really the process to blame – our application issuing DDL statements, without appropriate timeouts, was the problem. In fact, our estimate is that we would have hit this issue in at most 30 days.
Here's how we can simulate the exact situation above:
-- Simulate autovacuum lock, client=1
world=# BEGIN; LOCK TABLE city IN SHARE UPDATE EXCLUSIVE MODE;
LOCK TABLE
-- On a separate psql client client, client=2
UPDATE city SET population = 412000 WHERE id = 253;
UPDATE 1
-- Updates succeed, autovacuum not blocking reads/writes
-- as expected
-- Attempt to issue DDL statement, simulating partition creation, client=2
-- This will be rolled back automatically
world=# BEGIN; ALTER TABLE city ADD COLUMN district_short character(3) not null; ROLLBACK;
-- Hangs indefinitely, any queries to read/write to city are now blocked by this statement
-- On yet another separate psql client, client=3
UPDATE city SET population = 412000 WHERE id = 253;
-- Should hang indefinitely waiting in queue behind the DDL statement
-- Back on client=1
ROLLBACK;
-- This should unblock client 2
-- Which in turn will unblock client 3How did we fix it?
We are no stranger to the issue above[4]. We run zero downtime schema migrations frequently. When we run these migrations, we ensure that they are safe by setting appropriate timeouts (lock_timeout, statement_timeout). This prevents our migrations from waiting indefinitely to acquire a lock, and in turn from blocking read/write access to the relevant tables.
However, we were caught off-guard. We run the DDL statements to create partitions via a time-based job, and when writing it we forgot to use the same protection mechanisms we have in place for schema migrations.
While investigating what caused this incident, we learned a tonne more about PostgreSQL internals: vacuuming, MVCC and locks. To summarise our learnings:
- Set appropriate timeouts. Always include appropriate timeouts for your DDL statements (
lock_timeoutandstatement_timeout). - Review your logging setup. Slow query and lock waits logs are invaluable in finding these issues, without these we'd not be able to root-cause this issue
- These logs do not paint a full picture, e.g. no logs when autovacuum starts
- It was tricky to determine that autovacuum was running, but we were glad to be able to prove it
- Read the docs, and question your assumptions and understanding. We were surprised to see the autovacuum process not releasing its lock.
- Prove your hypothesis. We learned so much more by not stopping at "seems good enough" when it came to our reasoning. Finding proof is not always the easiest route, but it is certainly more rewarding.
If you’re interested in solving problems like this, check our careers page, we’re hiring engineers!
[1] We are currently revisiting our architecture, and are considering replacing PostgreSQL with another solution to storing search results.
[2] Dropping or truncating tables are much faster than DELETE statements; the latter requires a table scan. (Read more)
[3] One may expect the search results table to be involved in the autovacuum lock up, instead of searches. However, in our architecture the search results table contained a foreign key constraint to the searches table. A nuance that we left out of the main text for simplicity.
[4] GoCardless Engineering has a post from 2015 on zero-downtime migrations. https://gocardless.com/blog/zero-downtime-postgres-migrations-the-hard-parts
References
https://www.braintreepayments.com/blog/safe-operations-for-high-volume-postgresql/
https://www.cybertec-postgresql.com/en/whats-in-an-xmax/
https://brandur.org/postgres-atomicity
https://devcenter.heroku.com/articles/postgresql-concurrency
https://brandur.org/postgres-queues#mvcc
https://blog.sentry.io/2015/07/23/transaction-id-wraparound-in-postgres


Latest posts
Introducing Duffel Cars: one API for flights, stays and now car rentals
Duffel Cars is here. Businesses can now embed car rentals from 40 global providers across 40,000+ locations in 200 countries, alongside Flights and Stays, through the same Duffel API — making Duffel a more complete one-stop shop for embedded travel.

Rippling chooses Duffel to power Rippling Travel
Rippling chose Duffel to power Rippling Travel, bringing flights and stays into its Spend Management suite so employees can book trips easily while finance teams manage travel spend in real time.
Data-Driven Travel: Using Analytics from the Duffel API to Make Smarter Business Decisions
Our latest blog post explores how companies and developers can use this tool to make smarter business decisions. Learn how to leverage booking data, implement dynamic pricing models, and use predictive modeling for future planning.

Introducing Duffel Cars: one API for flights, stays and now car rentals
Duffel Cars is here. Businesses can now embed car rentals from 40 global providers across 40,000+ locations in 200 countries, alongside Flights and Stays, through the same Duffel API — making Duffel a more complete one-stop shop for embedded travel.
Rippling chooses Duffel to power Rippling Travel
Rippling chose Duffel to power Rippling Travel, bringing flights and stays into its Spend Management suite so employees can book trips easily while finance teams manage travel spend in real time.
Data-Driven Travel: Using Analytics from the Duffel API to Make Smarter Business Decisions
Our latest blog post explores how companies and developers can use this tool to make smarter business decisions. Learn how to leverage booking data, implement dynamic pricing models, and use predictive modeling for future planning.